THM: Content Discovery
Ref:
Task1: What is Content Discovery?
In the context of web application security, what is content? Content can be many things, a file, video, picture, backup, a website feature. When we talk about content discovery, we’re not talking about the obvious things we can see on a website; it’s the things that aren’t immediately presented to us and that weren’t always intended for public access.
This content could be, for example, pages or portals intended for staff usage, older versions of the website, backup files, configuration files, administration panels, etc.
There are three main ways of discovering content on a website which we’ll cover. Manually, Automated and OSINT (Open-Source Intelligence).
What is the Content Discovery method that begins with M?
1
Manual
What is the Content Discovery method that begins with A?
1
Automated
What is the Content Discovery method that begins with O?
1
OSINT
Task2: Manual Discovery-Robots.txt
There are multiple places we can manually check on a website to start discovering more content.
Robots.txt
The robots.txt file is a document thattells search engines which pages they are and aren't allowed to show on their search engine results or ban specific search engines from crawling the website altogether. It can be common practice to restrict certain website areas so they aren’t displayed in search engine results. These pages may be areas such as administration portals or files meant for the website’s customers. This file gives us a great list of locations on the website that the owners don't want us to discover as penetration testers.
Take a look at the robots.txt file on the Acme IT Support website to see if they have anything they don’t want to list - To do this open Firefox on the AttackBox, and enter the url: http://10.10.35.220/robots.txt
(this URL will update 2 minutes from when you start the machine in task 1)
What is the directory in the robots.txt that isn’t allowed to be viewed by web crawlers?
1
2
3
User-agent: *
Allow: /
Disallow: /staff-portal
Task3: Manual Discovery-Favicon
Favicon
The favicon is a small icon displayed in the browser’s address bar or tab used for branding a website.
Sometimes when frameworks are used to build a website, a favicon that is part of the installation gets leftover, and if the website developer doesn’t replace this with a custom one, this can give us a clue on what framework is in use. OWASP host a database of common framework icons that you can use to check against the targets favicon https://wiki.owasp.org/index.php/OWASP_favicon_database. Once we know the framework stack, we can use external resources to discover more about it (see next section).
Practical Exercise:
On the AttackBox, open firefox and enter the url https://static-labs.tryhackme.cloud/sites/favicon/ here you’ll see a basic website with a note saying “Website coming soon…”, if you look at your tabs you’ll notice an icon that confirms this site is using a favicon.
Viewing the page source you’ll see line six contains a link to the images/favicon.ico file.

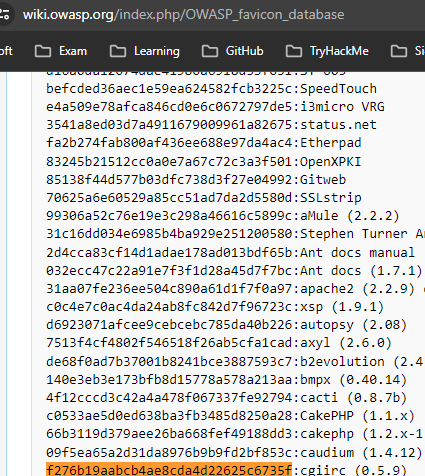
If you run the following command on the AttackBox, it will download the favicon and get its md5 hash value which you can then lookup on the https://wiki.owasp.org/index.php/OWASP_favicon_database.
1
2
3
4
5
6
7
8
9
10
11
12
13
Curl
user@machine$ curl https://static-labs.tryhackme.cloud/sites/favicon/images/favicon.ico | md5sum
-----
curl https://static-labs.tryhackme.cloud/sites/favicon/images/favicon.ico | md5sum
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1406 100 1406 0 0 20985 0 --:--:-- --:--:-- --:--:-- 20985
f276b19aabcb4ae8cda4d22625c6735f -
Note:
This curl will fail on the AttackBox if you are a free user, in which case you should use a VM for this. If your hash ends with 427e then your curl failed, and you may need to try it again. You could also run this on Windows in Powershell as shown below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
PS C:\> curl https://static-labs.tryhackme.cloud/sites/favicon/images/favicon.ico -UseBasicParsing -o favicon.ico
PS C:\> Get-FileHash .\favicon.ico -Algorithm MD5
---
root@ip-10-10-213-55:~# curl https://static-labs.tryhackme.cloud/sites/favicon/images/favicon.ico
Warning: Binary output can mess up your terminal. Use "--output -" to tell
Warning: curl to output it to your terminal anyway, or consider "--output
Warning: <FILE>" to save to a file.
root@ip-10-10-213-55:~# Get-FileHash .\favicon.ico -Algorithm MD5
Get-FileHash: command not found
root@ip-10-10-213-55:~# curl https://static-labs.tryhackme.cloud/sites/favicon/images/favicon.ico -UseBasicParsing -o favicon.ico
Enter proxy password for user 'seBasicParsing':
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1406 100 1406 0 0 18500 0 --:--:-- --:--:-- --:--:-- 18500
cgiirc
Task4: Manual Discovery-Sitemap.xml
Sitemap.xml
Unlike the robots.txt file, which restricts what search engine crawlers can look at, the sitemap.xml file gives a list of every file the website owner wishes to be listed on a search engine. These can sometimes contain areas of the website that are a bit more difficult to navigate to or even list some old webpages that the current site no longer uses but are still working behind the scenes.
Take a look at the sitemap.xml file on the Acme IT Support website to see if there’s any new content we haven’t yet discovered: http://10.10.35.220/sitemap.xml (open this in the FireFox browser on the AttackBox).
What is the path of the secret area that can be found in the sitemap.xml file? 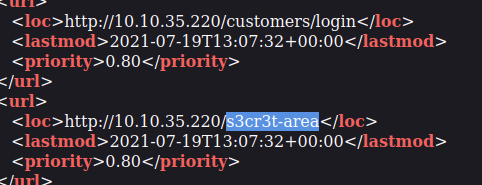
1
s3cr3t-area
Task5: Manual Discovery -HTTP Headers
HTTP Headers
When we make requests to the web server, the server returns various HTTP headers. These headers can sometimes contain useful information such as the webserver software and possibly the programming/scripting language in use. In the below example, we can see the webserver is NGINX version 1.18.0 and runs PHP version 7.4.3. Using this information, we could find vulnerable versions of software being used. Try running the below curl command against the web server, where the -v switch enables verbose mode, which will output the headers (there might be something interesting!).
i.e.
1
curl http://10.10.35.220 -v
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
curl
---
user@machine$ curl http://10.10.35.220 -v
* Trying 10.10.35.220:80...
* TCP_NODELAY set
* Connected to MACHINE_IP (MACHINE_IP) port 80 (#0)
> GET / HTTP/1.1
> Host: MACHINE_IP
> User-Agent: curl/7.68.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Server: nginx/1.18.0 (Ubuntu)
< X-Powered-By: PHP/7.4.3
< Date: Mon, 19 Jul 2021 14:39:09 GMT
< Content-Type: text/html; charset=UTF-8
< Transfer-Encoding: chunked
< Connection: keep-alive
What is the flag value from the X-FLAG header?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
root@ip-10-10-213-55:/# curl http://10.10.35.220 -v
* Rebuilt URL to: http://10.10.35.220/
* Trying 10.10.35.220...
* TCP_NODELAY set
* Connected to 10.10.35.220 (10.10.35.220) port 80 (#0)
> GET / HTTP/1.1
> Host: 10.10.35.220
> User-Agent: curl/7.58.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Server: nginx/1.18.0 (Ubuntu)
< Date: Fri, 16 Feb 2024 19:48:18 GMT
< Content-Type: text/html; charset=UTF-8
< Transfer-Encoding: chunked
< Connection: keep-alive
< X-FLAG: THM{HEADER_FLAG}
<
<!--
This page is temporary while we work on the new homepage @ /new-home-beta
-->
<!DOCTYPE html>
<html lang="en">
<head>
<title>Acme IT Support - Home</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="stylesheet" href="https://pro.fontawesome.com/releases/v5.12.0/css/all.css" integrity="sha384-ekOryaXPbeCpWQNxMwSWVvQ0+1VrStoPJq54shlYhR8HzQgig1v5fas6YgOqLoKz" crossorigin="anonymous">
<link rel="stylesheet" href="/assets/bootstrap.min.css">
<link rel="stylesheet" href="/assets/style.css">
</head>
<body>
<nav class="navbar navbar-inverse navbar-fixed-top">
<div class="container">
<div class="navbar-header">
<button type="button" class="navbar-toggle collapsed" data-toggle="collapse" data-target="#navbar" aria-expanded="false" aria-controls="navbar">
<span class="sr-only">Toggle navigation</span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<a class="navbar-brand" href="#">Acme IT Support</a>
</div>
<div id="navbar" class="collapse navbar-collapse">
<ul class="nav navbar-nav">
<li class="active"><a href="/">Home</a></li>
<li><a href="/news">News</a></li>
<li><a href="/contact">Contact</a></li>
<li><a href="/customers">Customers</a></li>
</ul>
</div><!--/.nav-collapse -->
</div>
</nav><div class="container" style="padding-top:60px">
<h1 class="text-center">Acme IT Support</h1>
<div class="row">
<div class="col-md-8 col-md-offset-2 text-center">
<img src="/assets/staff.png">
<p class="welcome-msg">Our dedicated staff are ready <a href="/secret-page">to</a> assist you with your IT problems.</p>
</div>
</div>
</div>
<script src="/assets/jquery.min.js"></script>
<script src="/assets/bootstrap.min.js"></script>
<script src="/assets/site.js"></script>
</body>
</html>
<!--
Page Generated in 0.04561 Seconds using the THM Framework v1.2 ( https://static-labs.tryhackme.cloud/sites/thm-web-framework )
* Connection #0 to host 10.10.35.220 left intact
Task6: Manual Discovery-FramworkStack
Framework Stack
Once you’ve established the framework of a website, either from the above favicon example or by looking for clues in the page source such as comments, copyright notices or credits, you can then locate the framework's website. From there, we can learn more about the software and other information, possibly leading to more content we can discover.
Looking at the page source of our Acme IT Support website (http://10.10.35.220), you’ll see a comment at the end of every page with a page load time and also a link to the framework’s website, which is https://static-labs.tryhackme.cloud/sites/thm-web-framework. Let’s take a look at that website. Viewing the documentation page gives us the path of the framework's administration portal, which gives us a flag if viewed on the Acme IT Support website.
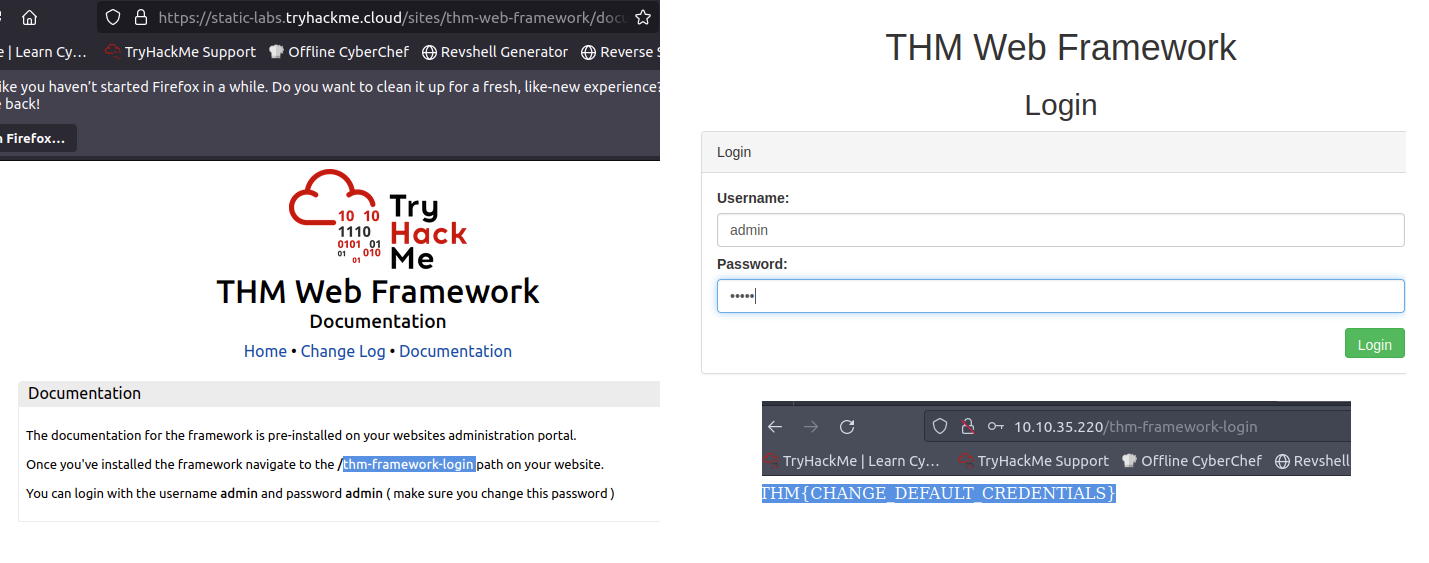
What is the flag from the framework’s administration portal?
1
THM{CHANGE_DEFAULT_CREDENTIALS}
Task 7: OSINT - Google Hacking / Dorking
There are also external resources available that can help in discovering information about your target website; these resources are often referred to as OSINT or (Open-Source Intelligence) as they’re freely available tools that collect information:
Google Hacking / Dorking
Google hacking / Dorking utilizes Google's advanced search engine features, which allow you to pick out custom content. You can, for instance, pick out results from a certain domain name using the site: filter, for example (site:tryhackme.com) you can then match this up with certain search terms, say, for example, the word admin
1
(site:tryhackme.com admin)
this then would only return results from the tryhackme.com website which contain the word admin in its content. You can combine multiple filters as well. Here is an example of more filters you can use:
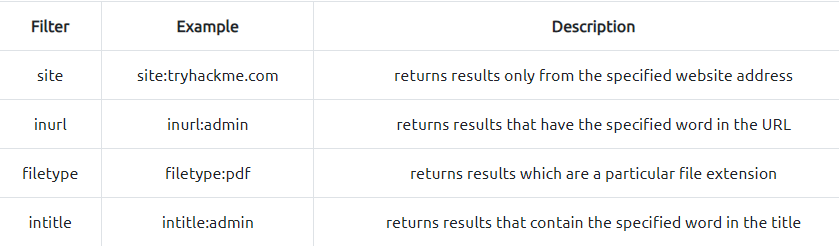
More information about google hacking can be found here: https://en.wikipedia.org/wiki/Google_hacking
What Google dork operator can be used to only show results from a particular site?
1
site:
Task 8 OSINT - Wappalyzer
Wappalyzer
Wappalyzer (https://www.wappalyzer.com/) is an online tool and browser extension that helps identify what technologies a website uses, such as frameworks, Content Management Systems (CMS), payment processors and much more, and it can even find version numbers as well.
What online tool can be used to identify what technologies a website is running?
1
Wappalyzer
Task 9 OSINT - Wayback Machine —
Wayback Machine
The Wayback Machine (https://archive.org/web/) is a historical archive of websites that dates back to the late 90s. You can search a domain name, and it will show you all the times the service scraped the web page and saved the contents. This service can help uncover old pages that may still be active on the current website.
What is the website address for the Wayback Machine? Answer format: **://**./**/
1
https://archive.org/web/
Task 10 OSINT - GitHub
GitHub
To understand GitHub, you first need to understand Git. Git is a version control system that tracks changes to files in a project. Working in a team is easier because you can see what each team member is editing and what changes they made to files. When users have finished making their changes, they commit them with a message and then push them back to a central location (repository) for the other users to then pull those changes to their local machines.
GitHub is a hosted version of Git on the internet. Repositories can either be set to public or private and have various access controls. You can use GitHub's search feature to look for company names or website names to try and locate repositories belonging to your target. Once discovered, you may have access to source code, passwords or other content that you hadn’t yet found.
What is Git?
1
version control system
Task 11 OSINT - S3 Buckets
S3 Buckets
S3 Buckets are a storage service provided by Amazon AWS, allowing people to save files and even static website content in the cloud accessible over HTTP and HTTPS. The owner of the files can set access permissions to either make files public, private and even writable. Sometimes these access permissions are incorrectly set and inadvertently allow access to files that shouldn’t be available to the public. The format of the S3 buckets is
1
2
3
http(s)://{name}.s3.amazonaws.com
where {name}
is decided by the owner, such as tryhackme-assets.s3.amazonaws.com. S3 buckets can be discovered in many ways, such as finding the URLs in the website’s page source, GitHub repositories, or even automating the process. One common automation method is by using the company name followed by common terms such as
1
{name}-assets, {name}-www, {name}-public, {name}-private, etc.
What URL format do Amazon S3 buckets end in?
1
s3.amazonaws.com
Task 12 Automated Discovery
What is Automated Discovery?
Automated discovery is the process of using tools to discover content rather than doing it manually. This process is automated as it usually contains hundreds, thousands or even millions of requests to a web server. These requests check whether a file or directory exists on a website, giving us access to resources we didn’t previously know existed. This process is made possible by using a resource called wordlists.
What are wordlists?
Wordlists are just text files that contain a long list of commonly used words; they can cover many different use cases. For example, a password wordlist would include the most frequently used passwords, whereas we’re looking for content in our case, so we’d require a list containing the most commonly used directory and file names. An excellent resource for wordlists that is preinstalled on the THM AttackBox is https://github.com/danielmiessler/SecLists which Daniel Miessler curates.
Automation Tools
Although there are many different content discovery tools available, all with their features and flaws, we’re going to cover three which are preinstalled on our attack box, ffuf, dirb and gobuster.
On the AttackBox execute the following three commands, targeting the Acme IT Support website and see what results you get.
Using ffuf:
1
ffuf -w /usr/share/wordlists/SecLists/Discovery/Web-Content/common.txt -u http://10.10.35.220/FUZZ
Using dirb:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
dirb http://10.10.102.28/ /usr/share/wordlists/SecLists/Discovery/Web-Content/common.txt
-----------------
DIRB v2.22
By The Dark Raver
-----------------
START_TIME: Fri Feb 16 20:42:21 2024
URL_BASE: http://10.10.102.28/
WORDLIST_FILES: /usr/share/wordlists/SecLists/Discovery/Web-Content/common.txt
-----------------
GENERATED WORDS: 4654
---- Scanning URL: http://10.10.102.28/ ----
==> DIRECTORY: http://10.10.102.28/assets/
+ http://10.10.102.28/contact (CODE:200|SIZE:3108)
+ http://10.10.102.28/customers (CODE:302|SIZE:0)
+ http://10.10.102.28/development.log (CODE:200|SIZE:27)
+ http://10.10.102.28/monthly (CODE:200|SIZE:28)
+ http://10.10.102.28/news (CODE:200|SIZE:2538)
==> DIRECTORY: http://10.10.102.28/private/
+ http://10.10.102.28/robots.txt (CODE:200|SIZE:46)
+ http://10.10.102.28/sitemap.xml (CODE:200|SIZE:1383)
---- Entering directory: http://10.10.102.28/assets/ ----
==> DIRECTORY: http://10.10.102.28/assets/avatars/
---- Entering directory: http://10.10.102.28/private/ ----
+ http://10.10.102.28/private/index.php (CODE:200|SIZE:49)
---- Entering directory: http://10.10.102.28/assets/avatars/ ----
-----------------
END_TIME: Fri Feb 16 20:42:34 2024
DOWNLOADED: 18616 - FOUND: 8
Using Gobuster:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
gobuster dir --url http://10.10.102.28/ -w /usr/share/wordlists/SecLists/Discovery/Web-Content/common.txt
===============================================================
Gobuster v3.0.1
by OJ Reeves (@TheColonial) & Christian Mehlmauer (@_FireFart_)
===============================================================
[+] Url: http://10.10.102.28/
[+] Threads: 10
[+] Wordlist: /usr/share/wordlists/SecLists/Discovery/Web-Content/common.txt
[+] Status codes: 200,204,301,302,307,401,403
[+] User Agent: gobuster/3.0.1
[+] Timeout: 10s
===============================================================
2024/02/16 20:41:12 Starting gobuster
===============================================================
/assets (Status: 301)
/contact (Status: 200)
/customers (Status: 302)
/development.log (Status: 200)
/monthly (Status: 200)
/news (Status: 200)
/private (Status: 301)
/robots.txt (Status: 200)
/sitemap.xml (Status: 200)
===============================================================
2024/02/16 20:41:13 Finished
===============================================================
What is the name of the directory beginning “/mo….” that was discovered? Answer format: /***
1
/Monthly
What is the name of the log file that was discovered? Answer format: /****.
1
/development.log